RAID이 무슨 약자인지부터 알아보자.
구글에 검색해보면 바로 확인 할 수 있다. Redundant Array of Independent Disks(독립 디스크의 중복 배열) 이라는 것의 약자라고 한다. 그럼 이제 이게 무엇이며 어디에 필요하고 왜 필요한지 알아볼 차례다.
1. RAID?
일단 Redundant Array of Independent Disk 의 약자라는 것은 간단한 검색 한방으로 알아 냈지만 이게 무엇인지 알아야 한다. 물론 구글링을 하면 많은 정보들이 넘쳐나며 이것이 무엇인지 알려주는 정보들이 많다. 구글링한 정보들을 내 방식대로 정리하는 것이 필요하기 때문에 적어두겠다.
독립 디스크의 중복배열이라는 것은 앞에 하둡의 설명 포스팅에서 하둡을 사용할때 사용되는 방식과 연결된다. 여러개의 하드디스크를 묶어 하나의 디스크처럼 사용하는 기술이라고 한다. 그렇다면 이것을 사용하는 이유는 무엇일까?
2. RAID 사용 이유?
- 대용량의 단일 볼륨을 사용하는 효과
- 디스크 I/O 병렬화로 인한 성능 향상
- 데이터 복제로 인한 안정성 향상
이 세가지가 주로 이야기 되는데 이해하는데 도움이 되도록 하나씩 내 방식대로 풀어서 글을 작성해 보도록 하겠다.
먼저
- 대용량의 단일 볼륨을 사용하는 효과
대용량의 단을 볼륨을 사용하는 효과라는 것은 작은 용량들의 하드디스크를 여러대 모아 데이터들을 분산시켜 저장하는 것으로 생각하면 될 것 같다. 100L의 물을 1L의 물병에 나눠담아두는 것과 같다.
- 디스크 I/O 병렬화로 인한 성능 향상
디스크 I/O 병렬화로 인한 성능 향상은 앞서 하둡에 관한 포스팅을 할 때 설명한 것과 같은 내용이다. 여러개의 하드디스크에 데이터를 읽는데 하나의 성능좋은 컴퓨터로 모든 데이터를 읽는거보다. 저렴한 컴퓨터 여러대를 사용하여 읽어들이는 것이 속도가 더 빨라 성능이 향상되는 것이다.
- 데이터 복제로 인한 안정성 향상
데이터 복제로 인한 안정성 향상은 이제 디스크 병렬화를 진행했을때의 문제점을 보완해주는 기능이다. 여러개의 하드디스크를 사용하다보면 한두개쯤 고장이 발생 할 수 있다. 이런 고장에 대처하기 위한 기술이다.
3. RAID에 레벨이 있다고?
RAID를 구글링 하다보면 갑자기 RAID에 관련하여 레벨이 있다고 나온다. 레벨이 왜 생겨났을까? 데이터를 저장하는 방식이나 관리하는 방식에 따라 발전되온 효율성의 문제때문에 생겨난 것 같다. 그리고 이제는 사용되지 않는 방식의 레벨과 자주 사용되는 방식, 문제점 등이 잘 설명되어 있는 여러 많은 포스팅들이 존재한다. 위키피디아에서 이미지들과 그 설명들이 자세하게 나와 있는데 그 정보들을 잘 정리해서 글을 작성한 글들이 많다.
나도 한번 글을 정리해 둘 필요가 있기 때문에 아래에 정리해 작성하려고 한다.
RAID 0

Striping 방식
RAID 0의 구성에 최소 2개의 디스크가 필요하며 RAID를 구성하는 모든 디스크에 데이터를 분할하여 저장한다. 전체 디스크를 모두 동시에 사용하기 때문에 단순하게 성능은 디스크를 몇개썼느냐에 따라 N배수로 성능이 증가하게 된다. 이 방식의 문제점은 하나의 디스크라도 문제가 발생할 경우 전체 RAID에 문제가 발생하는 치명적인 단점이 존재한다. 성능과 용량만을 봤을 때는 매우 좋은 선택일지 모르지만 안정성까지 고려했을 때는 최악의 선택일 수 있다. 실제 서버 운용에서 사용하기는 힘든 방식이라고 한다.
RAID 1
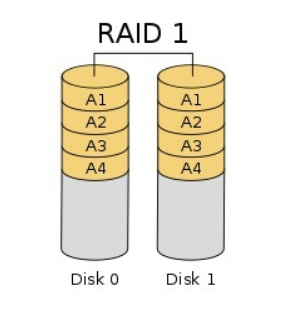
Mirroring 방식
RAID 1도 RAID와 마찬가지로 최소 2개의 디스크가 필요하게 되며 동일한 내용을 다른 디스크에 복제하여 사용하는 것이다. RAID 0 의 방식과는 전혀 반대로 안정성은 매우좋은 선택이지만 성능과 용량은 단일디스크 하나만 사용하는 것과 동일하기 때문에 성능면에서는 최악이라고 할 수 있다.
RAID 2(사용X)
현재 사용되지 않는 RAID 레벨
현재 사용되지 않는다고 한다. 굳이 사용되지 않는것 까지 적어야 하나 순간 고민을 했지만 일단 적어두기로 하자. 사용되지 않기 때문에 자세한 설명은 적어두지 않겠다.
RAID 3(사용X)

마찬가지로 사용되지 않는 RAID 레벨.
RAID 4

Block단위로 Striping을 하고 Error Correction을 위해 패리티 디스크를 1개 사용한다. 라고 되어있는데 이게 무슨 소린지 한번 내 방식대로 설명을 적어둘 필요가 있을 것 같다. 블럭단위로 데이터를 분할(Striping)을 한다는 것인데, 이제 하나의 데이터들을 다른 디스크에 분할해서 저장해 둔다는 것 같다. 위 그림을 보았을때 A라는 데이터를 3개로 분할해 Disk0~2에 A1, A2, A3로 구분해 나눠 저장하고, Disk3(*패리티 디스크:HDD에 장애가 발생한 뒤에 데이터를 복원하기 위해서 사용)를 사용해 오류검출수정(Error Correction)할 수 있는 디스크를 사용하는 것이다.
*최소 3개 디스크 구성, 1개의 디스크 에러시 복구 가능
RAID 5

제일 사용빈도가 높은 RAID 레벨.
이것은 RAID 4와 마찬가지로 Block단위로 Striping을 하고 Error Correction을 위해 패리티 디스크를 1개 사용한다고 하는데 RAID 4와 다른 점은 Disk3에 패리티 용도를 몰빵해 두었다면 이것은 데이터마다 디스크들에 패리티 디스크를 분산해 두었다는 것이다. A의 데이터를 Disk0 Disk1 Disk2에 두고 복원용을 1개 두어 Disk3에. B는 패리티 디스크를 Disk2로 사용한다. 이런식으로 패리티 디스크를 1개의 디스크에 저장해두는 것이 RAID 5의 포인트인 것 같다.
*최소 3개 디스크 구성, 1개의 디스크 에러시 복구 가능
RAID 6

RAID 5에서 용량을 줄이고 안정성을 높였다고 한다. RAID 5와 비교했을때 디스크 개수가 늘어난 것을 확인 할 수 있다. 디스크의 개수가 늘어났고 RAID 5와 동일하게 패리티를 분산하지만 다른점은 패리티 디스크를 2개 사용하는 점이다. 이러면 확실히 RAID 5 보다는 안정성을 높일 수 있을 것이다. RAID5 보다는 Disk의 개수가 늘어나기 때문에 비용이 조금 더 들어가고 관리하는 것이 조금 더 손이 갈 수 있을 것 같다.
*최소 4개 디스크 구성, 2개의 디스크 에러시 복구 가능
그외에 RAID의 레벨들을 붙여서 사용하는 방식들이 있는데 이건 그냥 이미지로 대체하도록 하자
RAID 0 + 1
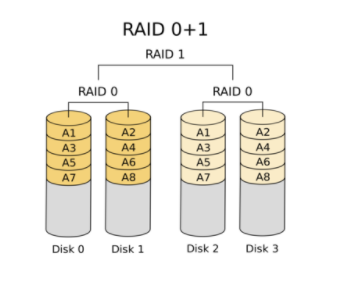
RAID 1 + 0

중첩 방식을 이런식으로도 사용할 수 있다고 한다.

RAID가 무엇인지. 그리고 왜 사용하는지 간단하게 알아보았다.
데이터를 공부하다보면 어쩌면 이런 데이터 저장방식 등의 기초들의 중요도를 잊고 공부를 하게 되는 것 같다. 급하게 취업을 목표로 쫓기듯 공부하면 이러한 기본적인 공부들은 건너뛰고 넘어가는 경우가 많아질 것 같지만 최대한 내가 궁금한 것들이나 확실하지 않은 것들은 이러한 포스팅들을 통해서 하나씩 이해하고 넘어가야 할 듯 하다. 이런 공부들이 어쩌면 내가 계속 공부를 해 나가면서 막히는 부분이 있거나 이해하기 어려운 것들의 돌파구가 되어 줄 수 도 있지 않을까?
아무튼 너무 기초만 이해하려드는 것도 문제일 수 있지만 기초는 확실히 중요한듯
'Hadoop' 카테고리의 다른 글
| HDFS 라는 것도 알아보자(2) (0) | 2023.11.11 |
|---|---|
| HDFS 라는 것도 알아보자 (0) | 2023.09.19 |
| Hadoop을 알아보자 (1) | 2023.09.17 |